文稿分享记录:TiDB Operator 设计与实现
文章整理自在 DockOne 社区进行的一次文稿分享,由于临到开始前才知道分享形式是纯文稿的,所以只列了一下提纲,现场的文字会比较口语化,当然这也原汁原味还原了分享现场🤣(什么鬼)
正文
TiDB 简介
大家好,我是 PingCAP 的 Cloud 工程师吴叶磊,目前在做 TiDB Operator 相关的开发工作,很高兴今天能跟大家分享一下 TiDB Operator 这个项目背后的一些东西。
首先要说的当然是我们为什么要做 TiDB Operator,这得从 TiDB 本身的架构开始说起。下面是 TiDB 的架构图:
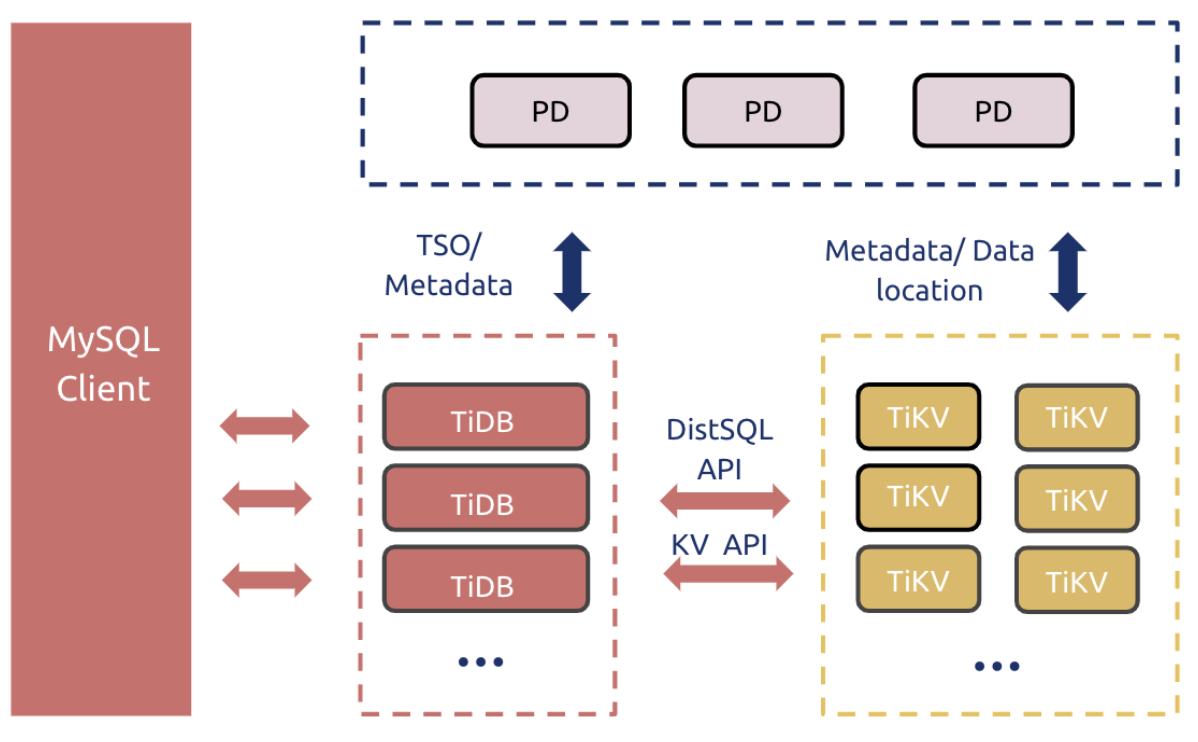
其中,TiKV 是一套分布式的 Key-Value 存储引擎,它是整个数据库的存储层,在 TiKV 中,数据被分为一个个 Region,而一个 Region 就对应一个 Raft Group,使用 Raft 协议做 Log Replication 来保证数据的强一致性。那么自然容易想到,我们只要水平增加 TiKV 节点数,再把数据切成更多的 Region 均匀分布在这些节点上,就能实现存储层的水平扩展。
TiDB 则是计算执行层,负责 SQL 的解析和查询计划优化,真正执行 SQL 时则通过 TiKV 提供的 API 来访问数据。
最后是 PD,PD 是集群的“大脑”,它一方面是是集群的 metadata server,TiKV 中的数据分布情况都会通过心跳上报给 PD 存储起来;另一方面又承担集群数据调度的任务,我们前面说 TiKV 要把数据拆成更多的 Region 均匀分布到节点上,什么时候拆、怎么拆、拆完分配到哪些节点上这些事情就都是 PD 通过调度算法来决定的。从直观上,PD 其实有点像 Kubernetes 里的 Control Plane。
TiDB Operator 简介
这么一套架构的优势是分层清晰,指责明确,每一层都可以独立地做功能扩展和规模上的水平伸缩。但是这对于运维管理来说,是一个巨大的挑战,再加上 TiDB 本身的一些比较复杂的分布式共识算法和事务算法,可以说是把整个 TiDB 的运维入门门槛拉得相当高。另一方面,传统的基于虚拟机的部署方式也不能很好地发挥 TiDB 水平伸缩和故障自动转移的潜力。所以其实我们在内部很早就在尝试使用 Kubernetes 来编排管理 TiDB 集群,甚至在这个开源的 TiDB Operator 之前,我们还有一版废弃掉的 TiDB Operator。最后的事实也确实证明我们一直以来的选择和投入是正确的,相信大家听了后面的分析,也会认同这一点。
接下来我们正式进入 TiDB Operator 的解读。其实 Operator 模式在 Kubernetes 社区已经不新鲜了,现在大部分流行的有状态应用都有自己的 Operator。但回顾一下 Operator 的一些概念仍然非常必要。
我们知道 Kubernetes 里两个很重要的概念就是声明式 API 和控制循环。所有的 API 对象都是对用户意图的记录,再由控制器去 watch 这些意图,对比实际状态,执行调谐(reconcile)操作来驱动集群达成用户意图。Kubernetes 本身有很多的内置 API 对象,比如 ReplicaSet 表达我们需要一个应用有几个实例,DaemonSet 表达我们希望在部分被选中的节点上每个节点运行且只运行一个实例。那我们该怎么向 Kubernetes 表达 “我需要一个 TiDB 集群呢“?答案就是定义一个用于描述 TiDB 集群的对象,在 Kubernetes 中,目前有两种方式可以定义一个新对象,一是 CustomResourceDefinition(CRD)、二是 Aggregation ApiServer(AA),其中 CRD 是相对简单也是目前应用比较广的方法。TiDB Operator 就用 CRD 定义了一个 ”TidbCluster” 对象。
有了对象还没完,这个对象现在谁都还不认识它呢。这时候就是自定义控制器出场的时候了,我们的自定义控制器叫 tidb-controller-manager,它会 watch TidbCluster 对象和其它一些相关对象,并且按照我们编写的逻辑做调谐来驱动真实的 TiDB 集群向我们定义的终态转移。
CRD 加上控制器就是典型的 Operator 模式了。当然这还没完,很多逻辑控制器也是无能为力的,比如 Pod 的调度逻辑。这一块为了实现 TiDB 容器的自定义调度策略,我们编写了 Scheduler Extender。还有一些验证逻辑,比如某些特殊情况下,我们要阻止集群的变更,这样的逻辑就用 Admission Webhook 来实现。而在用户侧,我们则开发了 kubectl plugin 来做 TiDB 的一些特定操作。所以大家就可以知道,TiDB Operator 其实不止于 Operator,我们的核心理念是利用 Kubernetes 大量的扩展点,为 Kubernetes 全面注入 TiDB 的领域知识,把 Kubernetes 打造成 TiDB 的一个最佳底座。
这样做有两大好处(划重点):
- 一是在 Kubernetes 基于控制循环的自运维模式下,我们可以把 TiDB 的运维门槛降到最低,让入门用户也能轻松搞定水平伸缩和故障转移这些高级玩法;
- 二是我们基于 Kubernetes 的 Restful API 提供了一套标准的集群管理 API,用户可以拿着这个 API 把 TiDB 集成到自己的工具链或 PaaS 平台中,真正赋能用户去把 TiDB 玩好玩精。
TiDB Operator 部分特性解析
上面说了一些比较玄乎的、方法论上的东西,可能大家都觉得脚快够不着地了 。下面我们就讲一些技术干货,用一些功能场景来解析 TiDB Operator 的实现机制,更为重要的是,我们认为这里面的一些套路对于在 Kubernetes 上管理有状态应用是通用的,可能能给大家带来一些启发。
第一是 TiDB Operator 该怎么去构建一个 TiDB 集群。我们尝试过直接操作 Pod,最后的结论是工作量太大了,k8s 自己的控制器里处理了大量的 corner case,并且有大量的单测和 e2e 测试来保障正确性,我们要自己再去实现一遍成本很高。因此我们最后的选型是 TiDB Operator 分别为 PD、TiKV、TiDB 创建一个 StatefulSet,再去管理这些 StatefulSet 来实现优雅升级和故障转移等功能。大家也可以看到有很多社区的 Operator 都是这么做的,而且部分没有这么做的 Operator 已经开始反思了,比如 https://github.com/elastic/cloud-on-k8s/issues/1173。确实按照我们的经验,管理有状态应用的 Operator 往往做到后来发现是需要自己实现 statefulset 80%的功能的,选择直接管理裸 Pod 就有点吃力不讨好了 。🤔
第二个是 Local PV,大部分存储型应用对磁盘性能是相当敏感的,因此 Local PV 是一个必选项。好在现在 Kubernetes 的 Local PV 支持已经比较成熟了,也有 local-pv-provisioner 来辅助创建 Local PV。但一个很让人头大的问题是用了 Local PV 之后,Pod 就和特定节点绑死了,节点故障后要调度到其它机器必须手动删除 PVC,这其实不是编排层能解决的问题,因为本地磁盘相比于背后通常会有三副本的网络存储本身就是不可靠的,使用本地磁盘的应用必须得在应用层做数据冗余。当然,TiDB 的存储层 TiKV 本身就是多副本高可用的,这种情况下我们采取的策略是不管旧的 Pod,直接创建新 Pod 来做故障转移,利用 TiKV 本身的数据调度把数据在新 Pod 上补齐。
接下来就是故障转移怎么做的问题。我们知道 StatefulSet 提供的语义保证是相同名字的 Pod 集群中同时最多只有一个,也就是假如发生了节点宕机,StatefulSet 是不会帮助我们做故障转移的,因为这时候 Kubernetes 并不知道是节点宕机还是网络分区,也就是它无法确定节点上的 Pod 还在不在跑。我们假设挂掉的 Pod 叫 tikv-0,那这时候 k8s 再创建一个 tikv-0 就脑裂了。当然了,在公有云上不会有这个问题,因为公有云上 Node Controller 会通过公有云 API 检查节点是不是真的消失了,假如是的话就会移除节点,那 k8s 就知道 tikv-0 不可能再运行,可以做故障转移了。可惜一难接一难😂,故障转移之后 Pod 又会碰到找不到 Local PV 的问题而 Pending🤣……
我们最终的解决方案是在 Tide cluster 对象的 status 中记录当前挂掉的 Pod,这个挂掉是指一方面 k8s 认为 Pod 挂了,另一方面,TiDB 集群,也就是 PD 也认为这个实例挂了,这个非常重要,因为我们实际场景中就遇到过因为单边网络问题 apiserver 认为节点掉线而其实正常运行的,这时候 PD 就救了我们一命。我们在控制循环中专门同步这些状态,一旦两面都确认某个 Pod 以及 Pod 中的实例挂了,我们就在 status 里记录下来。而另一个扩缩容控制循环会检查这个 status,假如有挂掉的实例,就给 StatefulSet 的副本数+1,实现故障转移。示意图如下:
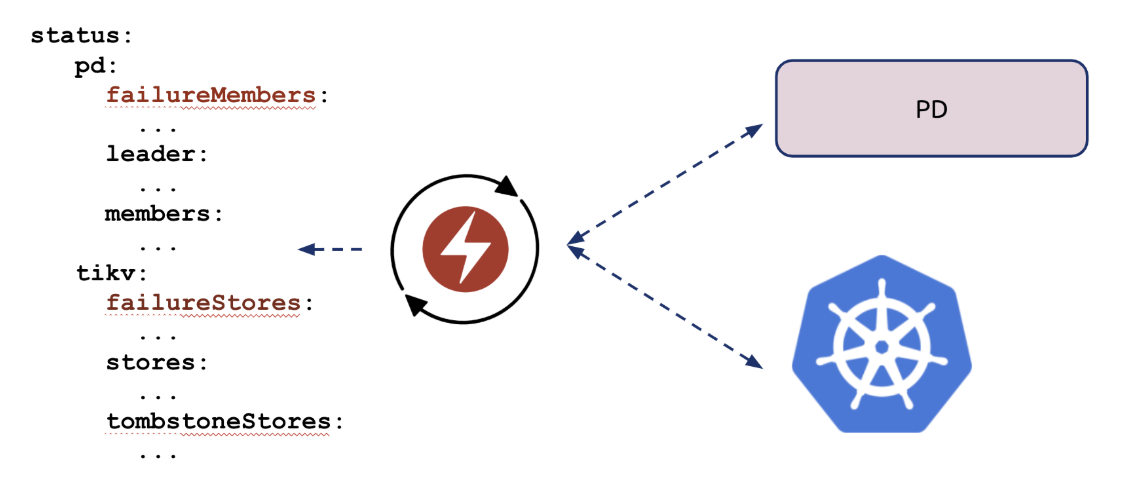
大家可以看到,控制器里是结合了 k8s 的信息和 PD 的信息去更新这个 failureStore 字段。
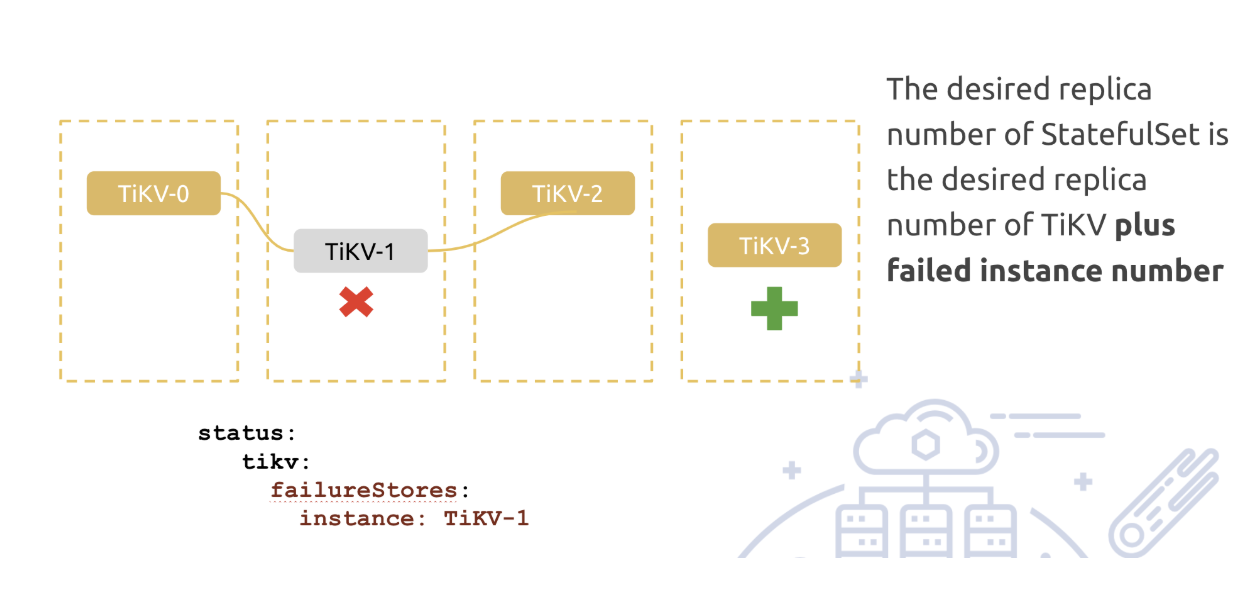
当我们确认 k8s 层面和业务层面(PD)都认为实例恢复正常后,我们就会从 failureStore 中删除对应实例,自动把实例数降下来,当然对于 PD 我们是这么做的,对于 TiKV,我们把删除 failureStore 这一步交给了用户,避免节点迁移次数过多,数据迁移太频繁影响集群性能。从这个 case 我们可以看到,在自定义控制器里糅合业务状态(来自业务,比如 TiDB 的 PD)与基础设施状态(来自 k8s)是重要且必要的。
第三个想说的是优雅升级,以 TiKV 为例,优雅升级就是在升级前主动逐出待升级实例上的所有 Raft Group 的 Leader,避免出现请求失败。大家可能会说这个用 preStopHook 可以做,但 preStopHook 的超时时间是一个比较难确定的东西,而且也不够灵活,我们最后选择是在 Controller 中实现,示意如下:
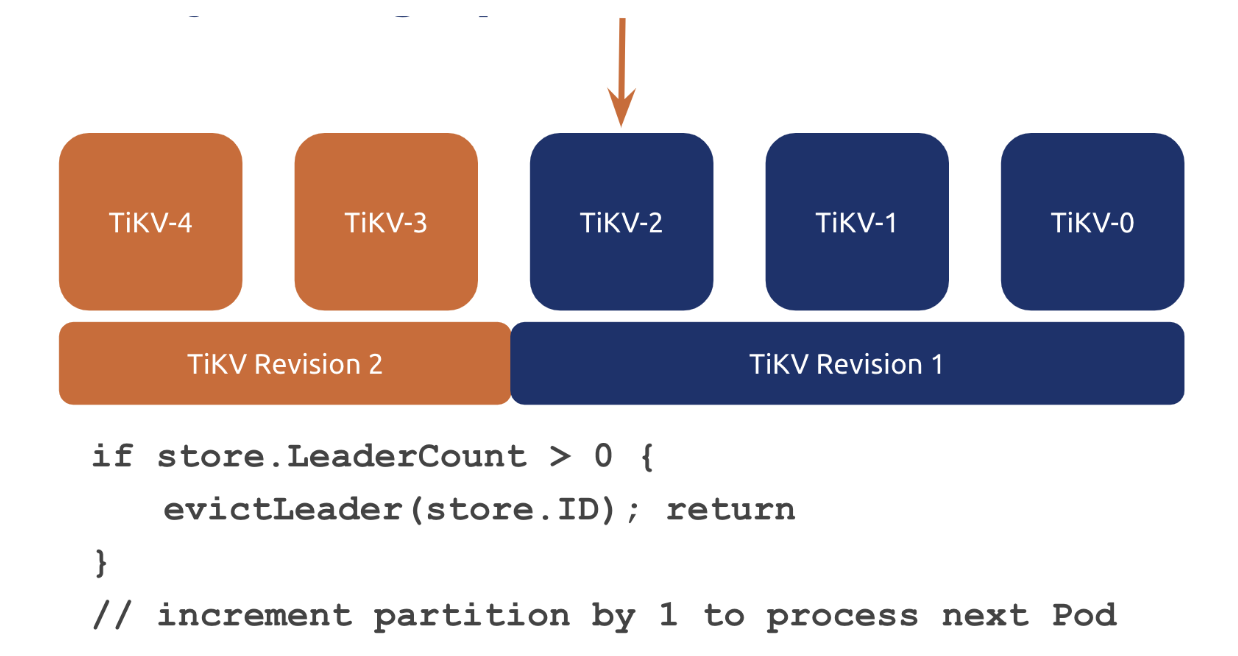
大家可以看到,我们其实用 StatefulSet 的 partition 字段来控制哪些序号可以被升级到新版本,哪些要呆在旧版本。升级开始时,partition = 节点数-1(这里分享时写错了,见后文 QA),也就是所有的 Pod 都不升级,然后呢,我们会去判断下一个待升级的 Pod 上是否存在 Leader,假如存在就进行逐出,逐出之后就 return 了,因为控制循环会不断进入,所以我们就会不断检查目标 Pod 上的 leader 是否逐出完了,一旦逐出完毕,就会往下走,将 partition - 1,让 k8s 把目标 Pod 升级到新版本,这样不断循环,确保每个节点在升级前都已经清干净了 leader,做到业务完全无损。后续呢,我们希望把这个功能放到 ValidatingAdmissionWebhook 上来实现,这样呢,可以做到功能与 controller 完全正交,大大提升可维护性,具体的方案我在个人博客里也有记录 https://aleiwu.com/post/tidb-opeartor-webhook/ (不是广告(才怪 🤪
我们在控制器里还有很多这样和 TiDB 本身的架构和特性深度集成的功能设计,所以大家可以看到,做一个 Operator 的前提条件是要对你要运维的系统架构做到了若指掌,甚至对源码也要有所了解。
说了很多的 tidb-controller-manager,最后说一下 tidb-scheduler,tidb-scheduler 其实是利用 k8s 本身的调度器扩展机制开发的,我们把 kube-scheduler 和 tidb-scheduler 打到了一个 pod 里,并且整个注册为 ”tidb-scheduler“,这样所有标记了使用该 schduler 的 pod 就能走到我们所定制的调度逻辑。
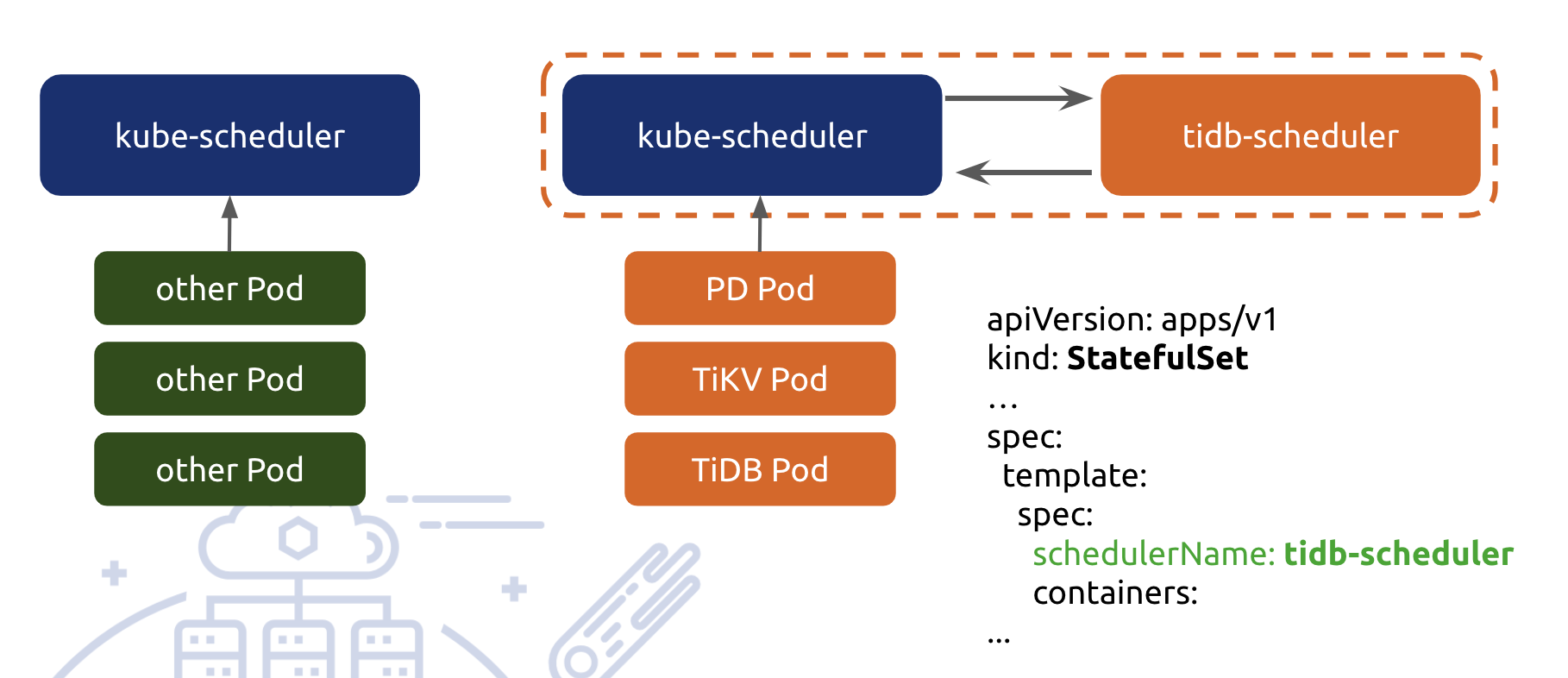
这里讲一个调度策略作为例子,PD 的高可用调度,PD 里内嵌了一个 etcd,所以它是一个基于 quorum 的共识系统,需要 majority 也就是超过一半的节点存活来保证可用性,我们的调度目标就是不在一台机器上部署超过半数的 PD 节点。你可能认为用 inter-pod anti-affinity 也能实现这个需求,但其实不是这样的。
anti-affinity 有两种,soft 和 hard,对于 soft 的反亲和性,当无法满足反亲和时,Pod 仍会被调度到同一个节点上,而 hard 则禁止这种情况出现。我们举个一个看看反亲和性为什么不能完美满足 quorum based 的系统调度需求:
我们假设现在有 3 个 node,5 个 pd 实例,那么下面这样的排布是能接受的:
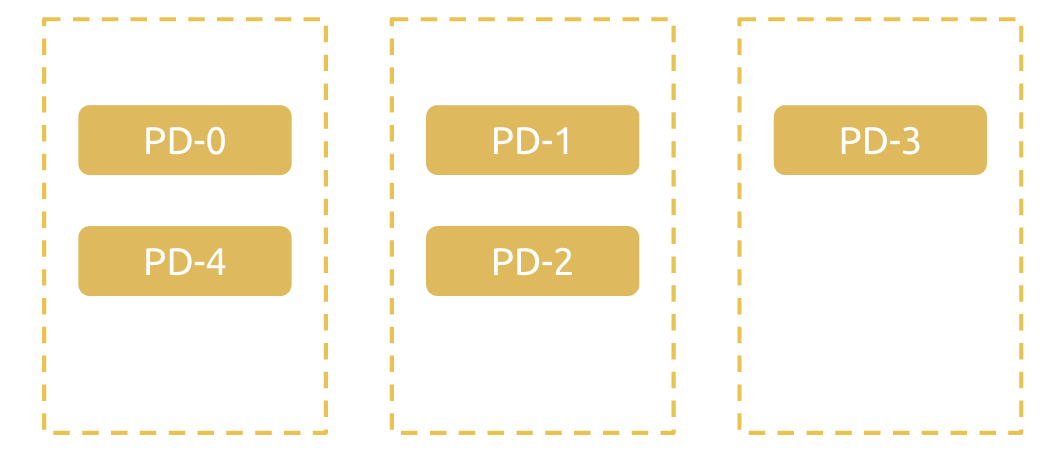
假如我们使用 hard 的反亲和性,这个拓扑无法接受; 假如我们使用 soft 的 f反亲和性,假设现在其中一个节点挂了,那么 Pod 就会转移到其它节点上,这时候由于 k8s 没有 de-schedule 机制,即使我们恢复了挂掉的节点,集群拓扑也不会转移回来; 那么 tidb-scheduler 中是怎么做的呢?策略也很简单,对于每个 Node,我们假设 Pod 调度到了目标 Node 上,再计算上面的实例数是否大于一半,假如是的话,就在 filter 阶段剔除这个 Pod。使用了这样的策略之后,大家可以推演一下,上面的拓扑是可以调度出来的,而且当节点挂掉之后,PD 实例会 Pending,不会带来一个存在风险的拓扑结构。
小结
时间有限,只能分享这么多了。最后呢,是用 operator 管理有状态应用的一点点总结:
- 站在巨人的肩膀上,尽量复用 k8s 原生对象;
- 使用 local pv 必须在应用层实现数据冗余;
- operator 要尽可能多地去结合业务状态,通过 apiserver 推导出的业务状态在大规模集群下未必准确;
- 不要只着眼于自定义控制器,k8s 的扩展点还有很多,善加利用能够大幅降低复杂度;
最后的最后,TiDB Operator https://github.com/pingcap/tidb-operator 也即将在本月 GA 了,还有很多来不及分享的特性等着大家,欢迎大家到时候关注。
QA
Q1:升级开始时,partition = 节点数-1,也就是所有的 Pod 都不升级,为啥是partition = 节点数-1?
A:这里要纠错一下,是 pod ordinal 从 0 开始计数,大于或等于 partition 序号的 pod 会被升级 ,所以最大的序号是节点数-1,最开始的 partition 是等于节点数,分享时表达错了(我自己也记错了),抱歉😅;
(这里其实是我在分享时犯错了,虽然看到问题反应过来了,但还是非常尴尬,感觉自己像个沙雕)
Q2:还有就是驱逐leader成功了怎么防止要升级的pod重新被选为leader
A:我们实际上是在 PD 中提交了一个驱逐 leader 的任务,PD 会持续保证驱逐完毕后没有新 leader 进来,直到升级完毕后,由控制器移除这个任务;
Q3:集群规模多大?多少 pod node ?
A:我们在 Kubernetes 上内部测试的规模较大的集群有 100 + TiKV 节点 50+ TiDB 节点,而每位研发都会部署自己的集群进行性能测试或功能测试;
Q4: 请问你们实现精准下线某一个pod 的功能了嘛,因为statefulset是顺序的?如何实现的?可以分享下思路嘛?
A:这个功能在 1.0 中还没有实现,我们计划在 1.1 中实现这个特性。
Q5:想了解下数据库容器化,推荐使用localpv吗,有没有哪些坑或最佳实践推荐?我们在考虑mysql数据库容器化以及中间件容器化,是选择localpv还是线下自建ceph集群?
A:Local PV 其实不是一个选项,而是一个强制因素,因为网络盘的 IOPS 是达不到在线存储应用的生产环境需求的,或者说不是说线上完全不能用,而是没法支撑对性能要求比较高的场景。MySQL 的运维我相对不是很清楚,假如 MM 能够做到双副本冗余强一致的话,那理论上就能用。大多数中间件比如 Kafka、Cassandra 都有数据冗余,这些使用 local pv 在理论上都是没问题的。
Q6:看你的方案感觉k8s和pd的逻辑结合在一起了,二者之间如何互通?会有代码互相侵入吗?明白了,就好像问题2驱逐问题,pd收到驱逐任务,k8s控制器不断的检查是否驱逐成功,如果成功就开始升级,对吧?
A:这就是自定义控制器的绝佳场景了,k8s 和 pd 本身完全没有交互,是控制循环在同步两边的状态,一方面控制循环会把 PD 记录的集群状态塞到 TidbCluster 对象的 status 里面,另一方面控制循环在将实际状态向期望状态转移时,也会生成一些 PD 的任务和操作子(Opeartor)提交到 PD 中来调谐集群状态。
最后
最后当然是招人啦,假如你对我们正在做的事情感兴趣,无论是 Cloud 也好数据库研发也好,都以联系 [email protected] 投递简历勾搭。