我的 Promtheus 到底啥时候报警?
最近又被问到了 Prometheus 为啥不报警,恰好回忆起之前经常解答相关问题,不妨写一篇文章来解决下面两个问题:
- 我的 Prometheus 为啥报警?
- 我的 Prometheus 为啥不报警?
从 for 参数开始
我们首先需要一些背景知识:Prometheus 是如何计算并产生警报的?
看一条简单的警报规则:
- alert: KubeAPILatencyHigh
annotations:
message: The API server has a 99th percentile latency of {{ $value }} seconds
for {{ $labels.verb }} {{ $labels.resource }}.
expr: |
cluster_quantile:apiserver_request_latencies:histogram_quantile{job="apiserver",quantile="0.99",subresource!="log"} > 4
for: 10m
labels:
severity: critical这条警报的*大致*含义是,假如 kube-apiserver 的 P99 响应时间大于 4 秒,并持续 10 分钟以上,就产生报警。
首先要注意的是由 `for` 指定的 Pending Duration。这个参数主要用于降噪,很多类似响应时间这样的指标都是有抖动的,通过指定 Pending Duration,我们可以 过滤掉这些瞬时抖动,让 on-call 人员能够把注意力放在真正有持续影响的问题上。
那么显然,下面这样的状况是不会触发这条警报规则的,因为虽然指标已经达到了警报阈值,但持续时间并不够长:

但偶尔我们也会碰到更奇怪的事情。
为什么不报警?
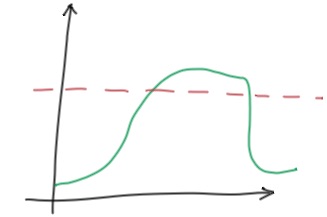 (图二: 为啥不报警)
(图二: 为啥不报警)
类似上面这样持续超出阈值的场景,为什么有时候会不报警呢?
为什么报警?
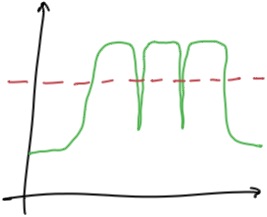 (图三: 为啥会报警)
(图三: 为啥会报警)
类似上面这样并未持续超出阈值的场景,为什么有时又会报警呢?
采样间隔
这其实都源自于 Prometheus 的数据存储方式与计算方式。
首先,Prometheus 按照配置的抓取间隔(`scrape_interval`)定时抓取指标数据,因此存储的是形如 (timestamp, value) 这样的采样点。
对于警报, Prometheus 会按固定的时间间隔重复计算每条警报规则,因此警报规则计算得到的只是稀疏的采样点,而警报持续时间是否大于 `for` 指定的 Pending Duration 则是由这些稀疏的采样点决定的。
而在 Grafana 渲染图表时,Grafana 发送给 Prometheus 的是一个 Range Query,其执行机制是从时间区间的起始点开始,每隔一定的时间点(由 Range Query 的 `step` 请求参数决定) 进行一次计算采样。
这些结合在一起,就会导致警报规则计算时“看到的内容”和我们在 Grafana 图表上观察到的内容不一致,比如下面这张示意图:
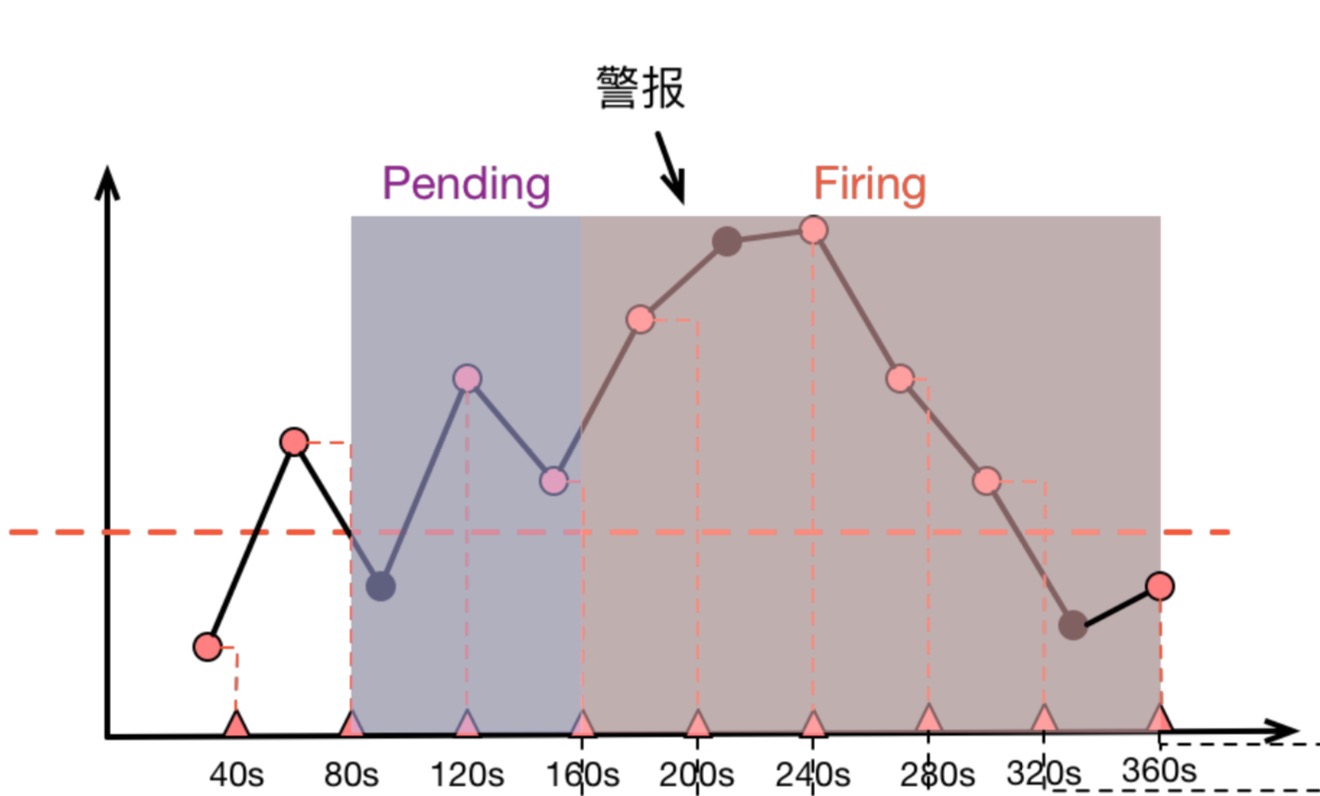
上面图中,圆点代表原始采样点:
- 40s 时,第一次计算,低于阈值
- 80s 时,第二次计算,高于阈值,进入 Pending 状态
- 120s 时,第三次计算,仍然高于阈值,90s 处的原始采样点虽然低于阈值,但是警报规则计算时并没有”看到它“
- 160s 时,第四次计算,高于阈值,Pending 达到 2 分钟,进入 firing 状态
- 持续高于阈值
- 直到 360s 时,计算得到低于阈值,警报消除
由于采样是稀疏的,部分采样点会出现被跳过的状况,而当 Grafana 渲染图表时,取决于 Range Query 中采样点的分布,图表则有可能捕捉到 被警报规则忽略掉的”低谷“(图三)或者也可能无法捕捉到警报规则碰到的”低谷“(图二)。如此这般,我们就被”图表“给蒙骗过去,质疑起警报来了。
如何应对
首先嘛, Prometheus 作为一个指标系统天生就不是精确的——由于指标本身就是稀疏采样的,事实上所有的图表和警报都是”估算”,我们也就不必 太纠结于图表和警报的对应性,能够帮助我们发现问题解决问题就是一个好监控系统。当然,有时候我们也得证明这个警报确实没问题,那可以看一眼 `ALERTS` 指标。`ALERTS` 是 Prometheus 在警报计算过程中维护的内建指标,它记录每个警报从 Pending 到 Firing 的整个历史过程,拉出来一看也就清楚了。
但有时候 ALERTS 的说服力可能还不够,因为它本身并没有记录每次计算出来的值到底是啥,而在我们回头去考证警报时,又无法选取出和警报计算过程中一模一样的计算时间点, 因此也就无法还原警报计算时看到的计算值究竟是啥。这时候终极解决方案就是把警报所要计算的指标定义成一条 Recording Rule,计算出一个新指标来记录计算值,然后针对这个 新指标做阈值报警。kube-prometheus 的警报规则中就大量采用了这种技术。
到此为止了吗?
Prometheus 警报不仅包含 Prometheus 本身,还包含用于警报治理的 Alertmanager,我们可以看一看上面那张指标计算示意图的全图:
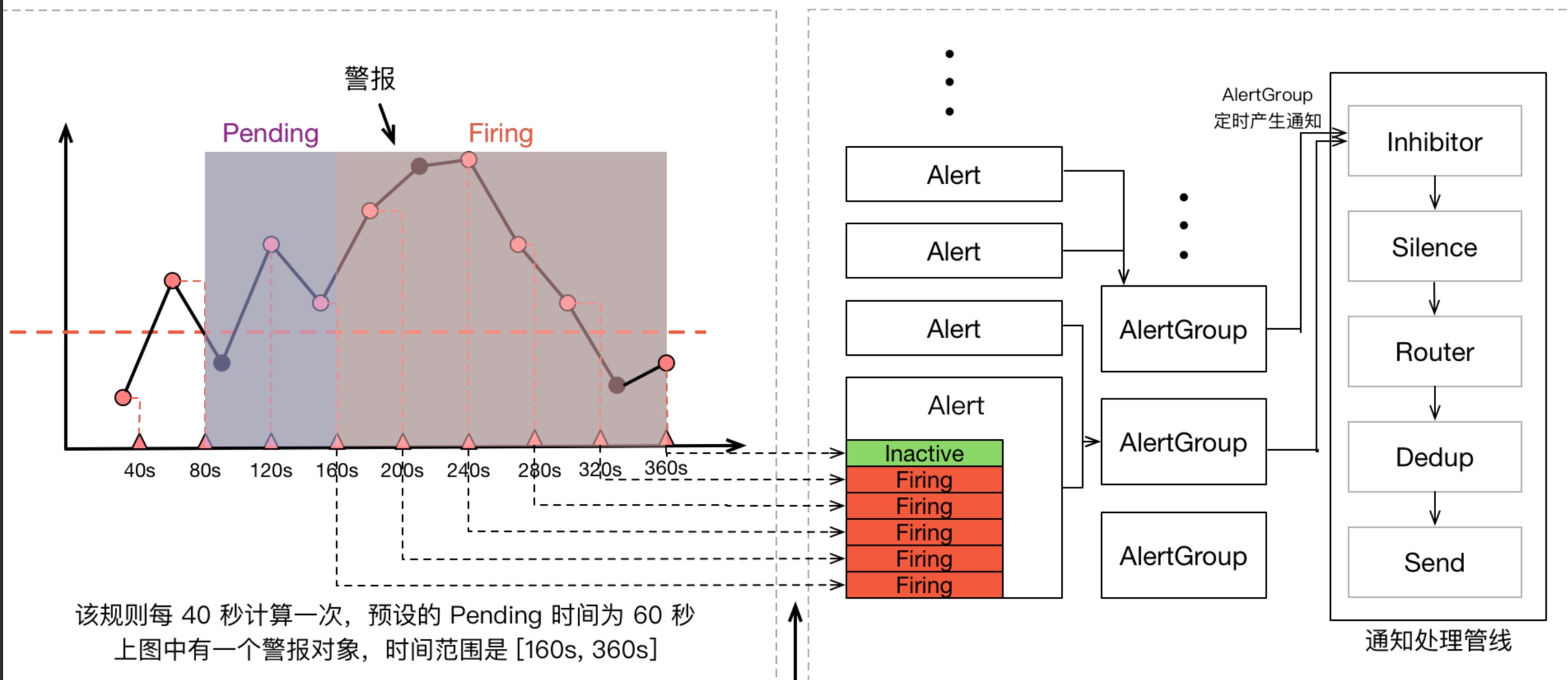
在警报产生后,还要经过 Alertmanager 的分组、抑制处理、静默处理、去重处理和降噪处理最后再发送给接收者。而这个过程也有大量的因素可能会导致警报产生了却最终 没有进行通知。这部分的内容,之前的文章 搞搞 Prometheus:Alertmanager 已经涵盖,这两篇内容加在一起,也算是能把开头的两个问题解答得差不多了吧😂。