Linux Slab 导致的内存使用率误报警
free命令的输出buff/cache部分并不等同于/proc/meminfo中的Buffer+Cached。警报规则中最常见的内存使用率计算方式也存在一些问题。
背景
最近在整理监控,碰到一位同事反馈问题:
内存监控报警报过来是大于 90%,但是我们看了下,实际使用只有 50% 多。
这个 “50%” 来自于 free -g:
# free - g
total used free shared buff/cache available
Mem: 31 17 0 0 13 6
Swap: 0 0 0这么看来,机器上约有 13G 的内存属于 buff/cache,应当能在需要时被回收。而在我们的警报规则中,内存使用率的计算方式是(Sigar 和 阿里云云监控 也都是这么算的):
(MemTotal - (MemFree + Buffers + Cached)) / MemTotal那么理论上根据 free 的输出结果,使用率算出来应该是 60% 不到,为什么会触发报警呢?
排查
登录到机器上看了一眼 /proc/meminfo,问题一下子就清楚了:
# cat /proc/meminfo
MemTotal: 32780412 kB
MemFree: 715188 kB
MemAvailable: 7264108 kB
Buffers: 16708 kB
Cached: 799300 kB
SwapCached: 0 kB
Active: 17793344 kB
Inactive: 375212 kB
Active(anon): 17354764 kB
Inactive(anon): 1132 kB
Active(file): 438580 kB
Inactive(file): 374080 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 832 kB
Writeback: 0 kB
AnonPages: 17352688 kB
Mapped: 146796 kB
Shmem: 3328 kB
Slab: 13096500 kB
SReclaimable: 6139152 kB
SUnreclaim: 6957348 kB
KernelStack: 58912 kB
PageTables: 100304 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 16390204 kB
Committed_AS: 37371552 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 299088 kB
VmallocChunk: 34359282792 kB
HardwareCorrupted: 0 kB
AnonHugePages: 8628224 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 460672 kB
DirectMap2M: 22607872 kB
DirectMap1G: 12582912 kBSlab 部分使用了近 13G 的内存,而 Buffer 和 Cached 加起来只使用了几百兆而已,将上面的结果绘制一下,更加直观:
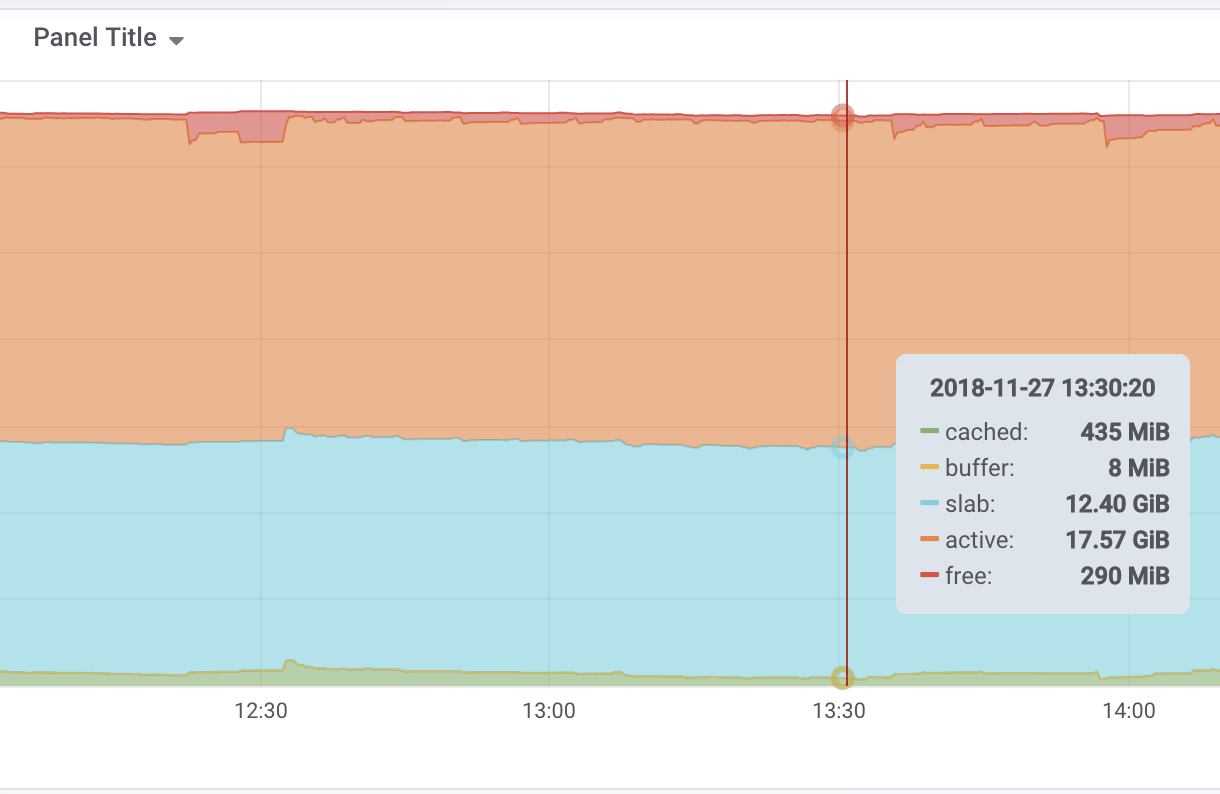
既然 Buffer 和 Cache 用量并不高,那么为什么 free 的输出当中 buffer/cached 足足占了 13G 呢? free 的 man page 是这么说的:
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and Slab in /proc/meminfo)
buff/cache
Sum of buffers and cache
available
Estimation of how much memory is available for starting new applications, without swapping. Unlike the data provided by the cache or free fields, this field takes into
account page cache and also that not all reclaimable memory slabs will be reclaimed due to items being in use (MemAvailable in /proc/meminfo, available on kernels 3.14,
emulated on kernels 2.6.27+, otherwise the same as free)可见 buff/cache = buffers + cache, cache 则包含了 Cached 和 Slab 两部分。 而Slab 本身也是可回收的(除去正在被使用的部分), /proc/meminfo 中用 SReclaimable 和 SUnreclaim 这两个指标标明了可回收的 Slab 大小与不可回收的 Slab 大小。在上面的场景中,SReclaimable 约有 6GB, 确实不应该发出警报。
到这里事情就明确了,文章开头的内存实际使用率算法其实是不科学的,我们需要找到一个更好的计算方式来做内存报警。
内存使用率怎么算最有报警价值?
根据上面的分析,我们首先要把 SReclaimable(可回收的 Slab 内存) 考虑进来:
(MemTotal - (MemFree + Buffers + Cached + SReclaimable)) / MemTotal但是 /proc/meminfo 里还有那么多数据,是否还有需要我们额外考虑的呢? 还有,在上面的算法中,我们认为所有的 Buffers,Cached,SReclaimable 部分都可以随时被回收,这科学吗?
这时候, free 命令的 “available” 部分的描述让我产生了兴趣:
available
Estimation of how much memory is available for starting new applications, without swapping. Unlike the data provided by the cache or free fields, this field takes into
account page cache and also that not all reclaimable memory slabs will be reclaimed due to items being in use (MemAvailable in /proc/meminfo, available on kernels 3.14,
emulated on kernels 2.6.27+, otherwise the same as free)available 的算法似乎非常符合我们的场景:它会考虑 Page Cache 和无法回收的 Slab 的内存,最后估算出一个”当前可用内存”。这个 PR 里是 available 的相关计算代码:
+ for_each_zone(zone)
+ wmark_low += zone->watermark[WMARK_LOW];
+
+ /*
+ * Estimate the amount of memory available for userspace allocations,
+ * without causing swapping.
+ *
+ * Free memory cannot be taken below the low watermark, before the
+ * system starts swapping.
+ */
+ available = i.freeram - wmark_low;
+
+ /*
+ * Not all the page cache can be freed, otherwise the system will
+ * start swapping. Assume at least half of the page cache, or the
+ * low watermark worth of cache, needs to stay.
+ */
+ pagecache = pages[LRU_ACTIVE_FILE] + pages[LRU_INACTIVE_FILE];
+ pagecache -= min(pagecache / 2, wmark_low);
+ available += pagecache;
+
+ /*
+ * Part of the reclaimable swap consists of items that are in use,
+ * and cannot be freed. Cap this estimate at the low watermark.
+ */
+ available += global_page_state(NR_SLAB_RECLAIMABLE) -
+ min(global_page_state(NR_SLAB_RECLAIMABLE) / 2, wmark_low);
+
+ if (available < 0)
+ available = 0;
+
/*
* Tagged format, for easy grepping and expansion.
*/
seq_printf(m,
"MemTotal: %8lu kB\n"
"MemFree: %8lu kB\n"
+ "MemAvailable: %8lu kB\n"在 available 的计算中,很重要的一点是 page cache 和 SReclaimable 也不是全都能安全回收的。因为在极端情况下,假设系统的 Cache 和 Slab 内存都被压缩得非常小,那 Performance 已经非常差了,基本等同于不可用状态。于是作者做了一个简单的经验估算:我们预估 pagecache / 2 和 slab_reclaimable / 2 是不可回收的
既然是估算,那泛用性就多多少少存在问题——我们并不知道上层的业务究竟是怎样的,业务代码究竟是怎么写的。比如说:
- 假设机器上跑了一个 Kafka Broker,Kafka 本身的 High Performance 非常依赖 page cache, 这时那我们认为它有 1⁄2 的 page cache 可以安全地被回收显然是有问题的;
- 假设机器上跑了一个 Storm 节点,频繁做文件操作产生大量
dentry_cache,那么这时候认为它只有 1⁄2 的SReclaimable内存可被回收又太保守了一点;
看来,真正要做好内存报警,必须得对上层业务的内存使用模型有透彻的认识。
最终方案
作为通用的规则提供方,我们自然没办法照顾到所有类型的上层业务。考虑到绝大部分线上的 workload 都是 web server,我们认为用 available 来计算内存使用率还是足够通用的,计算方式如下:
( MemTotal - MemAvailable) / MemTotal修改计算方式之后,大部分服务的”内存使用率”的计算结果都比旧的计算结果减少了近 10%,减少很多误报警。当然更重要的是,我们同步调整了内存的监控图表,加入了 Slab 相关的部分,让 oncall 的工程师能够第一时间掌握内存报警时 server 的内存使用状况。
参考资料
Interpreting /proc/meminfo and free output for Red Hat Enterprise Linux 5, 6 and 7, 关于 free 命令和 /proc/meminfo 的关联解释
Measure Linux web server memory usage correctly, 如何正确衡量服务器内存使用